Introducción
En Big Data hablamos de datos, datos para aquí datos para allá, pero ¿de dónde salen esos datos? ¿dónde los guardamos? y finalmente ¿qué hacemos con ellos? Eso es lo que vamos a responder en este artículo el día de hoy.
Contenido del Artículo
El flujo general de los datos
Sin entrar en tecnicismos vamos a explicar de forma simple cuál es el flujo general de los datos. Vamos a dividir en 4 etapas y a nivel conceptual lo que sería un entorno Big Data y estos son: Generación de los datos, Almacenamiento de datos, Predicción y Visualización de datos.
Generación de los datos
Almacenamiento de datos
Predicción a futuro
Visualización de los datos
Visualización de los datos
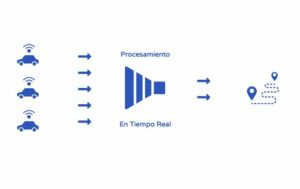
Generación de los Datos
La primera etapa consiste en generar los datos. Estos datos usualmente se generan a través de dispositivos IoT o Internet of Things. Estos son dispositivos que tienen conexión a internet y dependiendo del dispositivo puede enviar información de manera recurrente. Puede ser un sensor en un campo para medir la temperatura, o un GPS instalado en un autobus o una televisión en nuestro hogar.
Otra gran parte de la información se genera dentro de nuestras oficinas a través de sistemas transaccionales como lo son los CRM, ERP, softwares dentro de una empresa. Usualmente estos datos se almacenan para el uso diario en una base de datos transaccional.
Existen datos de fuentes abiertas que pueden funcionar para uno u otro caso de uso. Por ejemplo las redes sociales como Twitter o Facebook.
Los datos pueden salir de cualquier parte y lo importante es saber que se están generando y que más adelante los podemos utilizar.
Almacenamiento de los datos
Ya sabemos que los datos se están generando y la parte más importante, se podría decir, en temas específicamente de Big Data es almacenar toda esa información.
Esta etapa es crucial y consiste en centralizar toda la información que se está generando en un solo lugar. A este lugar se le conoce como Datalake y es simplemente como tirar toda la data ahí aún cuando no sabemos que vamos a hacer con ella.
Ahora surge otro tema, de toda la información que está entrando, seguro vamos a encontrar basura o datos que no nos sirven. Por ejemplo tweets que no tienen nada que ver con mi negocio, datos corruptos o incompletos, datos mal introducidos en una base de datos, etc.
También nos vamos a encontrar que el formato en que vienen los datos de Twitter son diferentes a los datos que provienen de un sistema transaccional y eso quiere decir que debemos estandarizar un poco cómo vamos a guardar la información.
A este tipo de tareas se le conoce como pre-procesar los datos o mejor dicho limpiar los datos. Una vez que limpiamos los datos los tenemos que guardar en un lugar que llamaremos Data Warehouse.
Las últimas dos etapas.
Perfecto, ya tenemos los datos almacenados, limpios, bien identificados ahora la pregunta sería ¿qué hacemos con los datos?
Pues dependiendo de la organización y las decisiones de los directivos, los datos pueden tomar dos caminos. El primero sería Visualización de los datos y el segundo Predicción de eventos en el futuro. Es en estas dos últimas etapas donde los datos son procesados para convertirse en información valiosa para el desarrollo de la compañía.
Visualización
Aquí es donde entran en juego los directivos de una compañía. Estas personas, que velan por el buen funcionamiento de una empresa, le surgen dudas y tienen que responderlas. Por ejemplo: el gerente general le gustaría saber cómo ha evolucionado su empresa a lo largo de los últimos 5 años.
Datos históricos
La idea de esta etapa de visualización, es responder las preguntas de los directivos a través del análisis de la información histórica de la compañía. Para responder a esta pregunta, el gerente general solicita un reporte de flujo de caja y ventas de la empresa de los últimos 5 años.
Claro, esta información histórica se representa a través de informes o reportes. Y muchos de ustedes dirán, «pero eso ha existido toda la vida». Y yo les contestaría, sí claro, pero ahora puedes tomar en cuenta datos de otras fuentes que antes por la naturaleza de la tecnología no podrías haber hecho.
Datos en tiempo real
Ya dejamos el histórico atrás, el gerente general ahora quiere saber cuál es el estado actual de la empresa. ¿Qué está pasando en este momento? ¿Cuántas ventas se han realizado hoy? ¿Se está llegando a la cuota establecida?
Para responder estas dudas, se obtiene información de datos en tiempo real de la situación actual de la empresa. Esta información se representa a través de Dashboards o cuadros de mando. Estos cuadros de mando suelen actualizarse a medida que van sucediendo las cosas.
Predicción
Para la etapa anterior, se necesitaba de la curiosidad de una persona y la habilidad de un analísta para entender cómo estaba funcionando la empresa. Hasta este momento no sabemos que es lo que va a pasar, tenemos datos históricos y datos en tiempo real. Pero y ¿qué pasa con el futuro? ¿Podemos predecir que tal le va a ir a la empresa?
Probablemente tengamos una idea vaga de lo que sería la empresa, pero con poca certeza. Gracias a la tecnología, ahora podemos poner en práctica tecnologías de Inteligencia Artificial y aprendizaje automático para que sea una computadora la que defina con un porcentaje de acierto qué es lo que va a pasar con la organización.
La inteligencia artificial utiliza los datos históricos para entrenarse y tener la capacidad de evaluar variables y así identificar posibles escenarios en el futuro.
En conclusión
Tenemos que saber cuál es el flujo general de los datos para saber cómo adquirirlos, dónde almacenarlos y luego qué hacer con ellos. Puede parecer obvio pero son conceptos que son importantes para entender cómo está estructurado un entorno del Big Data.
En este artículo hablamos de donde provienen los diferentes tipos de datos, mencionamos que existen repositorios llamados Datalakes y Data Warehouse y que una vez tenemos los datos, estos se procesan para convertirse en información valiosa para la compañía.