Introducción
El procesamiento de los datos se puede dar de varias formas, en tiempo real, por lotes o en una combinación entre las dos. Si quieres saber en que consisten cada tipo de procesamiento este artículo es para ti.
Como siempre te dejo un índice que te permitirá ir al tema que deseas directamente.
Contenido del Artículo
¿Qué significa procesar los datos?
Ya sabemos que los datos provienen de diferentes fuentes y en diferentes tipos. En Big Data cuando hablamos de procesar los datos hablamos de convertir todo lo que llega a nuestros repositorios en algo útil.
Dependiendo de la arquitectura podemos tener procesos de ETL(extract-transform-load) o ELT(extract-load-transform) que permiten limpiar y estandarizar los datos para que se adapten a nuestros requisitos. Más adelante los datos pueden volver a pasar por otra serie de transformaciones que nos permitirán utilizarlos de la forma que queramos.
Arquitectura y el Procesamiento
Existen varios tipos de procesamiento y varían de acuerdo a la arquitectura que se defina en el proyecto. La arquitectura de procesamiento por lotes, en tiempo real y la arquitectura lambda que viene siendo una mezcla entre dos.
Batch Processing o Procesamiento por Lotes
Streaming Processing o Procesamiento en Tiempo Real
Bonus: Arquitectura Lambda o Batch + Streaming
Procesamiento por Lotes o Batch Processing
Supongamos que tenemos una empresa que se dedica a vender computadoras a nivel mundial y almacenan toda la información en un Data Lake, (si no sabes que es un data lake te invito a que leas el artículo anterior donde explicamos a detalle cómo se almacenan los datos) donde permanecen sin ser tocados hasta ser requeridos para su procesamiento.
La empresa decide procesar los datos cada día a las 12:00 media noche para que al día siguiente, en la mañana, los directivos tengan sus reportes de ventas a nivel mundial.
Cuando se procesa la información, se utiliza todo el lote de datos que llegó desde las 12:01 A.M. hasta las 11:59 P.M. y ese es básicamente el concepto detrás del procesamiento por lote. En este caso particular tendríamos un lote que equivale a toda la data que se recopiló durante todo un día de trabajo.
Lote Día
22/2/2020
24 horas después
Lote Día
23/2/2020
24 horas después
Lote Día
24/2/2020
24 horas después
Lote Día
25/2/2020
Es importante considerar que nosotros decidimos cómo queremos procesar los datos y que el lote se puede configurar para que sea cuando nosotros queremos y las veces que queremos. El lote se puede definir por tiempo o también por tamaño o como uno realmente decida.
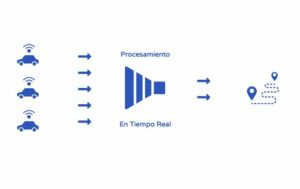
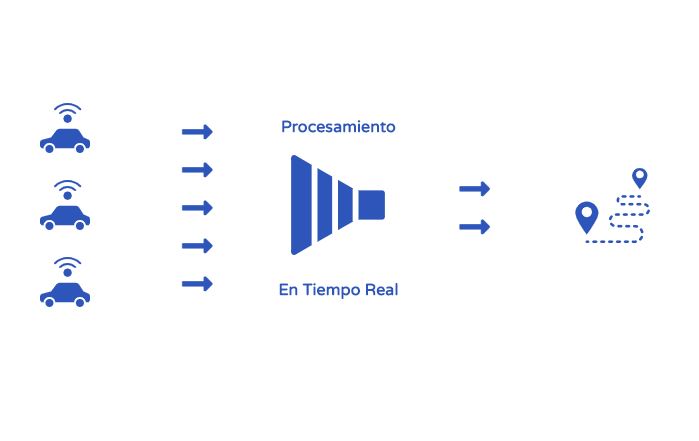
Procesamiento en tiempo real o Stream Processing
Luego de conocer el batch processing hablemos del stream processing o procesamiento en tiempo real. En este caso particular hablamos de procesar los datos apenas llegan, sin esperar un tiempo definido o ningún otro parámetro.
Un ejemplo muy particular puede ser utilizado por un servicio de transporte de carga que tenga instalado en cada vehículo un sensor de GPS.
La idea es saber si el vehículo ha sido robado y procesar cada hora no tendría mucho sentido porque ya le habrás dado al ladrón mucho tiempo para escapar.
Es por esta misma razón que se necesita procesar los datos para conocer la ubicación en tiempo real o lo más cercano al tiempo real. Tomando en cuenta que siempre hay un retraso mínimo producto de las capacidades del servidor, transferencia de información a través de las redes, entre otras cosas.
El GPS manda una señal de coordenadas geográficas de manera permanente cada segundo y el procesamiento consistiría, por ejemplo, en calcular velocidad, desplazamiento y marcar la trayectoria del vehículo a medida que cada coordenada va llegando.
Procesamiento
En Tiempo Real
Procesamiento
En Tiempo Real
Ubicación de la Flota
Micro batches o micro lotes
Muchas personas en este mundo del Big Data hacen referencia a un concepto bastante interesante y es que el procesamiento en tiempo real se podría considerar como micro batches o micro lotes, es decir, si el sensor de GPS manda las coordenadas cada 10 milisegundos lo que realmente tenemos son lotes definidos por una cantidad de tiempo muy pequeño.
A nivel conceptual basta con tener conocimiento de que existe y que va a depender del ingeniero a cargo para definirlo como procesamiento en tiempo real o como micro batches.
Arquitectura Lambda: batch + streaming
Puede darse el caso en que necesitemos tener una arquitectura que nos permita procesar la información de las dos maneras, en tiempo real y por lotes. La arquitectura lambda permite tener ambos tipos de procesamiento en un solo ecosistema.
Si seguimos con el mismo ejemplo de la empresa de carga, supongamos que nos gustaría predecir cuando el vehículo puede tener un desperfecto mecánico antes que suceda y poder prevenir accidentes.
Procesamiento Por Lotes
La empresa de carga decide evaluar todos los trayectos anteriores de cada vehículo y para esto decide procesar la información para obtener lo siguiente: ¿cuándo se hicieron las reparaciones anteriores?, ¿cuándo se hicieron los reportes?, ¿qué piezas se cambiaron? y enlazarlo con información de los recorridos de los vehículos como podrían ser kilómetros conducidos, velocidad a la que se produjo el desperfecto, entre muchas cosas más.
La empresa al procesar esta información decide entrenar un algoritmo de Machine Learning con los datos procesados de los lotes anteriores que vendrían siendo los recorridos.
Procesamiento en Streaming
Al tener los datos procesados de los recorridos anteriores y con los datos que están llegando en tiempo real, el algoritmo entrenado le permite dar en tiempo real una predicción de cuándo sucederá un accidente de acuerdo al estado actual del vehículo. Ese procesamiento de los datos en tiempo real, en conjunto con los lotes procesados anteriores es lo que se conoce como tener una arquitectura lambda.
¿Cuál tipo de procesamiento escoger?
Para saber que arquitectura vas a seleccionar debes saber que caso de uso tendrás. Si vas a utilizar algoritmos de predicción seguro necesitarás datos en tiempo real, pero si no es algo crítico la ruta puede ser utilizar el procesamiento por lotes.
Debes tenerlo claro desde el principio para evitar problemas más adelante. La arquitectura que escojas debes evaluarla muy bien porque cambiarla cuando el proyecto ya esté en producción será muy costoso. Siempre es bueno revisarla muy bien y conocer que uso se le dará a los datos antes de de definir el tipo de procesamiento.