Introducción
Este es el tercer artículo de la serie de Introducción al Big Data y no podemos continuar sin hablar sobre los 3 tipos de datos más comunes en Big Data. Vamos a dar pistas de cómo puedes identificar los tipos de datos y cómo pueden afectar tu ecosistema.
Si no has leído el artículo anterior sobre ¿Qué pasa con los datos en Big Data? te animo a que lo veas aquí. Trata sobre el flujo general de los datos desde que se generan hasta que se procesan para convertirse en información muy valiosa para la empresa.
Contenido del Artículo
Los 3 tipos de datos más comunes.
Datos, datos y más datos ¿de que más hablaríamos no? Ahora toca explicar sobre los tipos de datos que existen. Y los principales y más comunes son los siguientes: Datos Estructurados, Semi Estructurados y Datos No Estructurados.
Datos Estructurados
La forma más fácil de identificar los datos estructurados es precisamente a través de su estructura. Cuando hablamos de estructura nos referimos a información adicional que nos da detalles acerca del contenido del dato.
En algunos entornos se le conoce a esta información adicional como metadatos, en Big Data lo conocemos como Schema. Para aterrizarlo pondremos varios ejemplos:
Hoja de Cálculo de Excel
Vamos a suponer que tenemos un archivo excel que tiene 3 columnas: Nombre, Apellido y Edad. A pesar de que no sabemos el contenido de las filas, si tenemos conocimiento de la estructura, sabemos:
- El archivo tiene 3 columnas
- La primera y segunda columna hacen referencia al nombre y al apellido de una persona
- La tercera columna hace referencia a la edad de la persona.
| Nombre | Apellido | Edad |
|---|---|---|
| Erick | Reyes | 26 |
| José | Gutierrez | 50 |
| Fernanda | Graham | 36 |
| Bernardo | Hernandez | 13 |
Ahora, al ver los datos en la tabla con solo cuatro filas nos dimos cuenta de lo siguiente:
- El nombre y el apellido son de tipo cadena
- La columna de la edad es de tipo entero.
Esta información, que a priori, puede parecer simple, es la base de lo que llamamos datos estructurados.
Base de datos relacionales
Para los que ya tienen experiencia trabajando con base de datos transaccionales o relacionales, ya deben saber por qué toda la información almacenada en esa base de datos es estructurada.
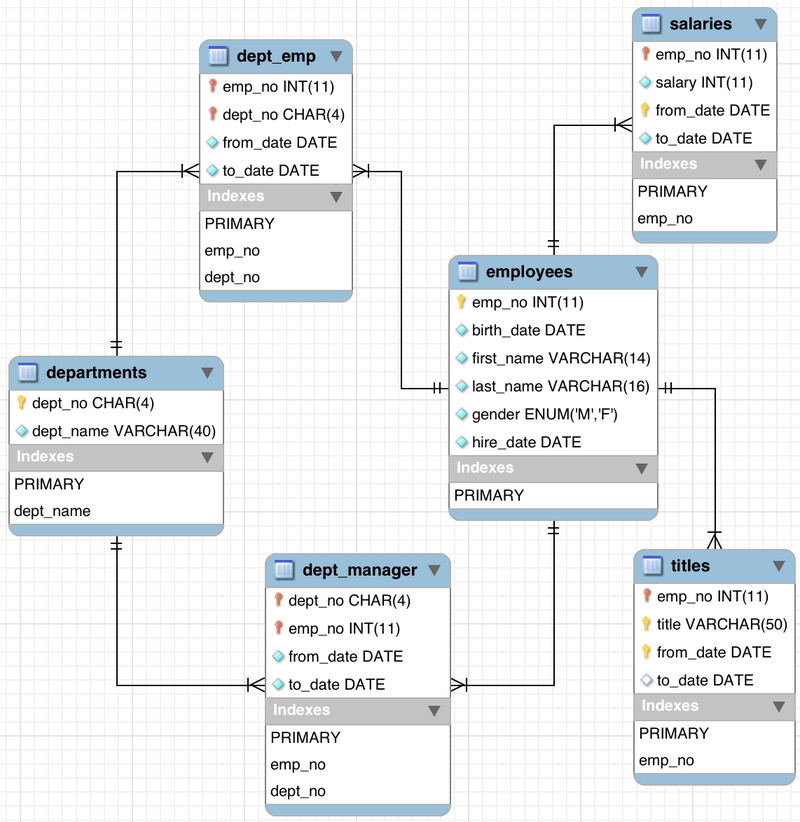
Todas las bases de datos relacionales utilizan tablas y todas las tablas tienen una estructura definida desde el momento en que se crean. Las tablas tienen columnas y cada columna tiene asociado un tipo de dato.
En la imagen a continuación, se aprecia que la base de datos tiene 6 tablas, cada una con sus campos definidos y asociados a un tipo de dato. Esta información es la que se conoce como esquema o estructura.
Datos No Estructurados.
Los datos no estructurados se conocen por NO tener una estructura definida. Es decir, que no tenemos idea de qué vamos a encontrar al ver ese dato. Vamos con el ejemplo:
Un documento de Word
Un documento de word está compuesto por muchas páginas las cuales no guardan una estructura definida. Sí, sabemos que tiene una cantidad X de páginas, que tiene un formato, pero no sabemos el contenido del documento.
Y no es solo el no saber el contenido de este documento en específico. Aunque supieramos el contenido, no se parecería en nada a otro documento de Word.
Cada documento de Word tiene su propio contenido y su propio formato y es por esta razón que se le conoce como datos no estructurados.

Datos Semi-Estructurados.
En este mundo no solo hay negro y blanco, también hay tonos grises y por esta razón no podemos dejar de lado los datos semi estructurados. Este tipo de dato es más común de lo que pensamos y consiste en tener una parte estructurada y otra sin estructura.
El caso más frecuente, o diría yo más conocido, sería el de un Tweet. Vamos a ver un tweet y su definición a nivel técnico.
{
"created_at": "Wed Oct 10 20:19:24 +0000 2018",
"id": 1050118621198921728,
"id_str": "1050118621198921728",
"text": "To make room for more expression, we will now count all emojis as equal—including those with gender and skin t… https://t.co/MkGjXf9aXm",
"user": {},
"entities": {}
} Un tweet se reconoce como dato semi estructurado debido a que cuenta con información que permite identificar parte del contenido. Por ejemplo:
- created_at: fecha en la que se creó el tweet.
- id: identificador del tweet.
- id_str: identificador en cadena
- user: información del usuario
- entities: información de las entidades (fotos, hashtags, mentions, etc)
¿Cómo es el comportamiento según los tipos de datos?
A diario se generan millones y millones de datos a nivel mundial y el tema más importante aquí es que los datos que más se generan son los datos no estructurados. Cada día se graban más videos, se toman mucho más fotos, se comparten audios y al final del día todos estos son datos no estructurados.
Si ponemos en una escala por cantidad de información, los datos estructurados son la minoría, luego vienen los semi-estructurados y finalmente los datos no estructurados.
De acuerdo al tipo de dato que vayas a trabajar necesitarás diferentes herramientas y sobre todo formas diferentes de procesar los datos para encontrarles utilidad. Al final del día esto es algo que debes considerar para definir arquitecturas, herramientas y presupuestos.
En conclusión
Existen 3 tipos de datos y varían de acuerdo a la estructura que tienen. Recordando que la estructura se le conoce como esquema y que el esquema nos brinda información valiosa sobre el contenido de los datos. Los 3 tipos de datos son: estructurados, no estructurados y semi-estructurados.